Added casper paper stuff
This commit is contained in:
parent
43ebb25299
commit
2ce0859ef5
|
|
@ -0,0 +1,362 @@
|
||||||
|
<h3>Casper The Friendly Finality Gadget</h3>
|
||||||
|
|
||||||
|
<p>This document describes a candidate design for the first implementation of Casper proof of stake on Ethereum. The proposal aims to achieve the key goals of deposit-based proof of stake including highly secure finality and low-cost consensus, but do so in a way that can be applied with minimal disruption to existing chains, including the current Ethereum proof of work chain. We describe the workings of the algorithm, show safety and liveness in a partially-synchronous fault-tolerance-theoretic model, and then proceed to describe the various considerations involving game-theoretic incentives. We will describe the algorithm in stages with increasing complexity, in order to show the core ideas first, and then bring in features such as validator set rotation and economic incentivization.</p>
|
||||||
|
|
||||||
|
<h3>Background</h3>
|
||||||
|
|
||||||
|
<p>Proof of stake has for a long time been viewed as a highly promising, but controversial, alternative to proof of work as a way of securing cryptoeconomic public blockchain consensus. Whereas proof of work measures economic consensus by measuring the quantity of computational resources that have been expended to "back" a particular state and history, proof of stake in simplest form seeks to replace physical mining with CPUs, GPUs and ASICs with "virtual mining" [cite], where economic consensus is measured by the economic resources inside the system that are committing to a given state and history.</p>
|
||||||
|
|
||||||
|
<p>However, early versions of proof of stake suffer from a flaw that is often called "nothing at stake" [cite], which states that if one naively builds a proof of stake algorithm by simply copying the intuitions and algorithms from proof of work, then the result is an algorithm where, in the event of a disagreement between whether to choose chain A or chain B, it is in every rational participant's interest to choose both. Unlike proof of work, where resources <em>on the outside</em> can be applied to either chain A or chain B but not both, in naive proof of stake the very fact of a chain split means that there is also a temporary split of the ledger of on-chain economic resources, and so a validator can use their copy of the resources on chain A to back chain A and a copy of their resources on chain B to back chain B.</p>
|
||||||
|
|
||||||
|
<p>PoW
|
||||||
|
<img src="https://raw.githubusercontent.com/vbuterin/diagrams/master/powsec.png" width="400px"></img> <br />
|
||||||
|
PoS
|
||||||
|
<img src="https://raw.githubusercontent.com/vbuterin/diagrams/master/possec.png" width="400px"></img> </p>
|
||||||
|
|
||||||
|
<p>Casper builds on a tradition that was started with the description of <a href="#">Slasher</a> in early 2014, which attempts to explicitly detect such "equivocation" (a common Byzantine-fault-tolerance-theoretic term for the act of sending two messages that contradict each other, in this case by simultaneously supporting two conflicting forks), and economically penalize validators that are caught engaging in such behavior in order to discourage it.</p>
|
||||||
|
|
||||||
|
<p><img src="https://raw.githubusercontent.com/vbuterin/diagrams/master/slasher1sec.png" width="400px"></img> </p>
|
||||||
|
|
||||||
|
<p>This solves nothing at stake (at the cost of an extremely weak synchrony assumption that will be discussed later), and ensures that such proof of stake algorithms can be at least as secure as proof of work. However, we can go further. It was soon discovered by Vlad Zamfir that consensus algorithms based on penalties could be made vastly more secure than consensus algorithms that are purely based on rewards, because there is an inherent asymmetry between the two. Whereas rewards are inherently limited in the size of the incentive that they offer, as every reward paid out must be paid out by the protocol, penalties can theoretically go much higher, potentially even all the way up to the entire pool of capital that the participant is participating in the proof of stake mechanism with.</p>
|
||||||
|
|
||||||
|
<p>This allows for the introduction of a notion of <em>economic finality</em>:</p>
|
||||||
|
|
||||||
|
<blockquote>
|
||||||
|
<p>A block, state or any constraint on the set of admissible histories can be considered <em>finalized</em> if it can be shown that if any incompatible block, state or constraint is also finalized (eg. two different blocks at the same height) then there exists evidence that can be used to penalize the parties at fault by some amount $X. This value X is called the <em>cryptoeconomic security margin</em> of the finality mechanism.</p>
|
||||||
|
</blockquote>
|
||||||
|
|
||||||
|
<p>However, such strict forms of penalty-based proof of stake run into another risk: the possibility of "getting stuck":</p>
|
||||||
|
|
||||||
|
<p><img src="https://cdn-images-1.medium.com/max/800/1*ftuBRQnM8v1kC0Lnvsh3zQ.jpeg" alt="" title="" /></p>
|
||||||
|
|
||||||
|
<p>A poorly designed algorithm could lead to a situation where it is not possible for any new block to be finalized, without at least some participants taking some action that would lead them to incur the penalty. Making an algorithm that can provide genuine finality, and that also avoids the possibility of getting stuck under all but the most exceptional circumstances, is a difficult challenge - but one that maps very well to problems that have already been studied for a long time under the aegis of Byzantine fault tolerance theory.</p>
|
||||||
|
|
||||||
|
<p>Algorithms such as PBFT, Paxos and HoneyBadger BFT [cite * 3] all try to achieve a similar goal, of achieving "consensus" between some group of nodes (sometimes called "processes"). An early attempt at defining the problem was through the Byzantine general's problem, where a group of generals are trying to coordinate on a specific plan for how to attack a city, but some of the generals may be traitors. The two goals are:</p>
|
||||||
|
|
||||||
|
<p>A. All loyal generals decide upon the same plan of action.
|
||||||
|
B. A small number of traitors cannot cause the loyal generals to adopt a bad plan. [cite Lamport 1982] </p>
|
||||||
|
|
||||||
|
<p>In a consensus algorithm implemented in real life, the "plan of action" to be decided on is that of which operations are to be processed in what order.</p>
|
||||||
|
|
||||||
|
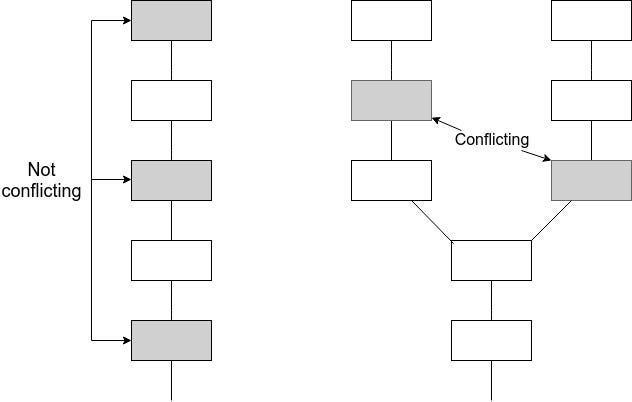
<p>In our case, the goal is not just to have one round of consensus to agree on a single value, but rather have ongoing rounds of consensus on an ever-growing chain. In a blockchain, every block contains the hash of the previous block, and so it is inherently linked to a history containing ancestor blocks going all the way back to some "genesis block" that was agreed to as one of the parameters of the protocol. Coming to consensus on a block inherently involves coming to consensus on all of its ancestors. Hence, the consensus algorithm must avoid not just coming to consensus on two conflicting blocks during one period, but rather it must also avoid coming to consensus on a block when it has already come to consensus on a block that conflicts with one of the block's ancestors.</p>
|
||||||
|
|
||||||
|
<p><img src="https://cdn-images-1.medium.com/max/800/1*ARu6mWJ2_oWXZR0UB13hkQ.jpeg" alt="" title="" /></p>
|
||||||
|
|
||||||
|
<p>We will start off by presenting "Minimal Slashing Conditions", a mechanism that has this property, and that can also arguably be used in other contexts as a simpler alternative to PBFT.</p>
|
||||||
|
|
||||||
|
<h3>Minimal Slashing Conditions</h3>
|
||||||
|
|
||||||
|
<p>This algorithm assumes the existence of an underlying <strong>proposal mechanism</strong>, which creates a chain of blocks which is constantly growing, and where given a set of blocks there is a way to deterministically calculate what is the "tip" of the chain. The chain may grow in a perfectly orderly fashion, with one block being added to the tip every few seconds, or it may sometimes have "forks" where a given parent block has two children and one of the two children is eventually abandoned, or in the worst case the chain may grow highly chaotically, with multiple long-running branches with the identity of the tip constantly switching from one chain to another.</p>
|
||||||
|
|
||||||
|
<p>The proposal mechanism working with a relatively high level of quality is not necessary for safety; provided more than 2/3 of nodes correctly follow the protocol conflicting checkpoints will not be finalized no matter how poorly the proposal mechanism behaves. However, if the proposal mechanism behaves very poorly, this may prevent liveness.</p>
|
||||||
|
|
||||||
|
<p>The proposal mechanism is deliberately kept abstract; this can be a dictator, it can be a round-robin scheme between the participants in the consensus, or, as in our case with hybrid Casper, it will be the original proof of work chain.</p>
|
||||||
|
|
||||||
|
<p>Every hundredth block in the chain is called a <strong>checkpoint</strong>, and the period between two checkpoints is called an <strong>epoch</strong>. We assume the existence of a set of <strong>validators</strong> V<sub>1</sub> ... V<sub>n</sub>, with sizes S(V<sub>1</sub>) ... S(V<sub>n</sub>); in hybrid proof of stake each of these validators must have put down a deposit, and the amount of ETH in that deposit becomes their size.</p>
|
||||||
|
|
||||||
|
<p>Validators have the ability to send two classes of messages:</p>
|
||||||
|
|
||||||
|
<pre><code>[PREPARE, epoch, hash, epoch_source, hash_source]
|
||||||
|
[COMMIT, epoch, hash]
|
||||||
|
</code></pre>
|
||||||
|
|
||||||
|
<p>The intention is that during epoch <code>n</code>, validators wait for the proposal mechanism to create a checkpoint during epoch <code>n</code> (say, with hash <code>H</code>), and then create a PREPARE message for epoch <code>n</code> and hash <code>H</code>. The <code>epoch_souce</code> and <code>hash_source</code> values should refer to the most recent (in terms of epoch number) checkpoint that they know about that has received prepares from a set of validators PREPSET where <code>sum_{v in PREPSET} S(V) >= sum_{v in ALL_VALIDATORS} S(V) * 2/3</code> (hereinafter, we will refer to a set which has this property as "at least two thirds of validators"; any reference to a fraction of the validator set should be read as being weighted by size). If/when at least two thirds of validators create a PREPARE for <code>n</code> and <code>H</code> with the same <code>epoch_source</code> and <code>hash_source</code>, validators should then send a message to COMMIT <code>n</code> and <code>H</code>. If two thirds of validators do this, the checkpoint is considered finalized.</p>
|
||||||
|
|
||||||
|
<p>Although we say that validators "should" follow the above set of rules, in many circumstances there is no way to enforce that they are in fact doing so. For example, consider a case where the proposal mechanism forks and creates two competing checkpoints at epoch <code>n</code>, C1 and C2. Suppose that a validator sees C1 five seconds before C2. According to the above rules, the validator <em>should</em> prepare on C1. However, if the validator prepares on C2, this cannot be detected, because for all we know the message containing C1 <em>could</em> have been delayed by six seconds en route to that validator's computer and so the validator could have seen C2 first.</p>
|
||||||
|
|
||||||
|
<p>However, what we <em>can</em> do is identify a few specific cases where there is clear evidence that a validator acted incorrectly, and in these cases penalize the validator heavily - in fact, we can even go so far as to take away their entire deposit.</p>
|
||||||
|
|
||||||
|
<p>We can do this by defining a set of "slashing conditions", where if any validator triggers one of the four conditions they will lose their entire deposit. The conditions are as follows:</p>
|
||||||
|
|
||||||
|
<p>[copy from medium post]</p>
|
||||||
|
|
||||||
|
<p>We would like to prove two properties about this mechanism:</p>
|
||||||
|
|
||||||
|
<ol>
|
||||||
|
<li><strong>Accountable safety</strong> : if two conflicting hashes get finalized, then it must be provably true that at least 1/3 of validators violated some slashing condition.</li>
|
||||||
|
<li><strong>Plausible liveness</strong>: unless at least 1/3 of validators violated some slashing condition, there must exist a set of messages that 2/3 of validators can send which finalize some new hash without violating some slashing condition.</li>
|
||||||
|
</ol>
|
||||||
|
|
||||||
|
<p>Details of a machine-verifiable proof in Isabelle can be <a href="https://medium.com/@pirapira/formal-methods-on-some-pos-stuff-e309775c2ab8">found here</a>. A proof sketch is as follows:</p>
|
||||||
|
|
||||||
|
<p>Suppose that two conflicting hashes C1 and C2 get finalized. This means that in some epoch e1, C1 has 2/3 prepares and 2/3 commits, and in some epoch e2, C2 has 2/3 prepares and 2/3 commits (if either of those sets of 2/3 prepares were missing, 2/3 of validators would have violated <code>PREPARE_REQ</code>).. First, consider the easy case where e1 = e2. Then, 2/3 prepares on C1 and 2/3 prepares on C2 require 1/3 of validators to have violated <code>NO_DBL_PREPARE</code>.</p>
|
||||||
|
|
||||||
|
<p>Now, without loss of generality, consider the case where e2 > e1. By <code>PREPARE_REQ</code> the 2/3 prepares on C2 imply 2/3 prepares during some previous epoch e2' < e2. This in turn implies 2/3 prepares during some epoch e2'', and so forth until one of two terminating cases:</p>
|
||||||
|
|
||||||
|
<p>(i) e2* = e1. Here, we have 2/3 prepares on C1, and 2/3 prepares on some ancestor of C2 which is not C1, and so 1/3 get slashed by <code>NO_DBL_PREPARE</code> <br />
|
||||||
|
(ii) e2* < e1. Here, we have 2/3 prepares with <code>epoch > e1</code> and <code>epoch_source < e1</code>, as well as 2/3 commits with <code>epoch = e1</code>. Hence, at least 1/3 of the preparers must have violated <code>PREPARE_COMMIT_CONSISTENCY</code> </p>
|
||||||
|
|
||||||
|
<p>Plausible liveness can be proven even more easily. Suppose that (i) P is the highest epoch where there are 2/3 prepares, and (ii) M is the highest epoch when any message has been sent. By (i) there were no honest commits with epoch above P, and so 2/3 of validators can safely prepare any value with epoch M+1, and epoch source P. They can then safely commit that value.</p>
|
||||||
|
|
||||||
|
<h3>Hybrid fork choice rule</h3>
|
||||||
|
|
||||||
|
<p>The mechanism described above ensures <em>plausible liveness</em>; however, it does not ensure <em>actual liveness</em> - that is, while the mechanism cannot get stuck in the strict sense, it could still enter a scenario where the proposal mechanism gets into a state where it never ends up creating a checkpoint that could get finalized.</p>
|
||||||
|
|
||||||
|
<p>Here is one possible example:</p>
|
||||||
|
|
||||||
|
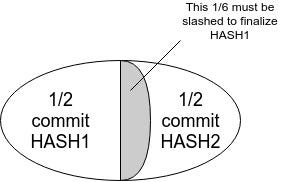
<p><img src="https://cdn-images-1.medium.com/max/800/1*IhXmzZG9toAs3oedZX0spg.jpeg" width="400px"></img></p>
|
||||||
|
|
||||||
|
<p>In this case, HASH1 or any descendant thereof cannot be finalized without slashing 1/6 of validators. However, miners on a proof of work chain would interpret HASH1 as the head and start mining descendants of it. In fact, when <em>any</em> checkpoint gets k > 1/3 commits, no conflicting checkpoint can get finalized without <code>k - 1/3</code> of validators getting slashed.</p>
|
||||||
|
|
||||||
|
<p>This necessitates modifying the fork choice rule used by participants in the underlying proposal mechanism (as well as users and validators): instead of blindly following a longest-chain rule, there needs to be an overriding rule that (i) finalized checkpoints are favored, and (ii) when there are no further finalized checkpoints, checkpoints with more (justified) commits are favored.</p>
|
||||||
|
|
||||||
|
<p>One complete description of such a rule would be:</p>
|
||||||
|
|
||||||
|
<ol>
|
||||||
|
<li>Start with HEAD equal to the genesis of the chain.</li>
|
||||||
|
<li>Select the descendant checkpoint of HEAD with the most commits (only checkpoints with 2/3 prepares are admissible)</li>
|
||||||
|
<li>Repeat (2) until no descendant with commits exists.</li>
|
||||||
|
<li>Choose the longest proof of work chain from there.</li>
|
||||||
|
</ol>
|
||||||
|
|
||||||
|
<p>The commit-following part of this rule can be viewed in some ways as mirroring the "greegy heaviest observed subtree" (GHOST) rule that has been proposed for proof of work chains. The symmetry is this: in GHOST, a node starts with the head at the genesis, then begins to move forward down the chain, and if it encounters a block with multiple children then it chooses the child that has the larger quantity of work built on top of it (including the child block itself and its descendants). Here, we follow a similar approach, except we repeatedly seek the child that comes the closest to achieving finality. A checkpoint is implicitly finalized if any of its descendants are finalized, and so we need to look at descendants and not just direct children. Finalizing a checkpoint requires 2/3 commits within a single epoch, and so we do not try to sum up commits across epochs and instead simply take the maximum.</p>
|
||||||
|
|
||||||
|
<h3>Adding Dynamic Validator Sets</h3>
|
||||||
|
|
||||||
|
<p>The above assumes that there is a single set of validators that never changes. In reality, however, we want validators to be able to join and leave.</p>
|
||||||
|
|
||||||
|
<h3>Economic Fundamentals</h3>
|
||||||
|
|
||||||
|
<p>The fault-tolerance-theoretic assumptions made so far simply assume that more than two thirds of every validator set is not willing to lose theire entire deposits, and given this assumption we can show safety. However, we must also show how the algorithm incentivizes liveness, and so so under several different sets of assumptions. We analyze the proof of stake component under both an uncoordinated choice model and a coordinated choice model. For now we assume that the underlying proof of work blockchain simply works, and ask our readers to accept this in light of uncoordinated choice modeling [cite] and empirical observations that coordinated attacks on proof of work have been rare so far, though in a later section we will discuss how validators can cooperate to overcome 51% attacks against the underlying proof of work layer.</p>
|
||||||
|
|
||||||
|
<h3>Protocol utility function</h3>
|
||||||
|
|
||||||
|
<p>We will start off by specifying a "protocol utility function", a function which can be computed on any chain and which outputs a value that represents the "quality" of the chain. A unit decrease in protocol utility should be understood to represent a unit decrease in user satisfaction; our main objective is to maximize expected protocol utility.</p>
|
||||||
|
|
||||||
|
<p>We define protocol utility as follows:</p>
|
||||||
|
|
||||||
|
<pre><code>sum_{block i = 1 ... n} -ln(i - LFE(i)) + c - M * SF_
|
||||||
|
</code></pre>
|
||||||
|
|
||||||
|
<p>Where:</p>
|
||||||
|
|
||||||
|
<ul>
|
||||||
|
<li>LFE(i) refers to the last epoch in the chain before block i that was finalized (in an optimally running chain, this is always i-1)</li>
|
||||||
|
<li>SF = 1 if a safety failure was detected in the most recent epoch, as defined by 1/3 of validators getting slashed, otherwise 0</li>
|
||||||
|
<li>c is the portion of commits in the current epoch</li>
|
||||||
|
<li>M is a (very large) constant</li>
|
||||||
|
</ul>
|
||||||
|
|
||||||
|
<p>Note that there is no single principled way to say what the protocol utility is; this is a question that ultimately rests on the values of the users of the system. However, we can defend the reasoning behind each component in the above formula.</p>
|
||||||
|
|
||||||
|
<p>The -M * SF term is self-explanatory; safety failures are very bad, as it means that events that appear to have been finalized, and that users may be relying on being finalized, suddenly become unfinalized. The -ln(i - LFE(i)) term is more complicated. What is it saying is that the amount of pain that users feel from having to wait <code>k</code> epochs for their transaction to be finalized is logarithmic in <code>k</code>. This can be justified inuitively: the difference between finality in 1 minute and 2 minutes feels similar in size to the difference between 1 hour and 2 hours. Another approach is to look at the possible set of blockchain applications, ranging from running games on them at the 100-1000 millisecond level, to retail payments at the 1-10 second level, other kinds of payments that currently take 1-10 minutes, and large institutional settlements that can take days, and see that they are roughly logarithmically distributed on the scale of the longest confirmation time that they could reasonably accept. The separate <code>c</code> term is there to show that even if a given epoch does not finalize, commits can still provide value, as a smaller number of commits on a given block can still make it harder to finalize competing blocks.</p>
|
||||||
|
|
||||||
|
<h3>Incentives</h3>
|
||||||
|
|
||||||
|
<p>We define the full set of incentives that we assign to validators in any given epoch as follows.</p>
|
||||||
|
|
||||||
|
<p>From the point of view of the state in which the incentives are being calculated, let us assume:</p>
|
||||||
|
|
||||||
|
<ul>
|
||||||
|
<li><code>e</code> is the epoch number</li>
|
||||||
|
<li><code>H</code> is the hash of the most recent checkpoint block</li>
|
||||||
|
<li><code>H_s</code> is the most recent justified checkpoint (ie. checkpoint with prepares from two thirds of the previous and current validator sets) that the state knows about </li>
|
||||||
|
<li><code>k</code> is a constant</li>
|
||||||
|
<li><code>TD</code> is the total size of deposits</li>
|
||||||
|
<li><code>LFE(e)</code> is the last finalized epoch</li>
|
||||||
|
<li><code>D</code> is a given validator's deposit size</li>
|
||||||
|
</ul>
|
||||||
|
|
||||||
|
<p>During any epoch, define <code>BASE_INTEREST = D * k / sqrt(TD)</code> and <code>PENALTY_FACTOR = D * k / sqrt(TD) * log(1 + e - LFE(e))</code>. Abbreviate:</p>
|
||||||
|
|
||||||
|
<ul>
|
||||||
|
<li><code>NCP</code> = non-commit penalty</li>
|
||||||
|
<li><code>NFP</code> = non-finality penalty</li>
|
||||||
|
<li><code>NPP</code> = non-prepare penalty</li>
|
||||||
|
<li><code>NCCP</code> = per-non-commit collective penalty</li>
|
||||||
|
<li><code>NPCP</code> = per-non-prepare collective penalty</li>
|
||||||
|
</ul>
|
||||||
|
|
||||||
|
<p>Assume all references to the five above variables in the remaining section are actually referring to <code>NCP * PENALTY_FACTOR</code>, <code>NFP * PENALTY_FACTOR</code>, etc.</p>
|
||||||
|
|
||||||
|
<p>We define the penalties as follows:</p>
|
||||||
|
|
||||||
|
<ul>
|
||||||
|
<li>If the epoch is not finalized, all validators pay <code>NFP</code></li>
|
||||||
|
<li>All non-committing validators pay <code>NCP</code></li>
|
||||||
|
<li>All non-preparing validators pay <code>NPP</code></li>
|
||||||
|
<li>Suppose <code>cp</code> is the minimal fraction of validators between the two validator sets that commits (eg. if 80% of the validators in the current dynasty commit and 68% of the validators in the previous dynasty do, <code>cp = 0.68</code>). All validators pay <code>NCCP * (1 - cp)</code>. Waived if 2/3 prepares are not found.</li>
|
||||||
|
<li>Suppose <code>pp</code> is the minimal fraction of validators between the two validator sets that prepares. All validators pay <code>NPCP * (1-pp)</code></li>
|
||||||
|
</ul>
|
||||||
|
|
||||||
|
<h4>Uncoordinated Choice</h4>
|
||||||
|
|
||||||
|
<p>In an uncoordinated choice model, we assume that there is a validator set V<sub>1</sub> ... V<sub>n</sub>, with deposit sizes |V<sub>1</sub>| ... |V<sub>n</sub>|, and each validator acts independently according to their own incentives. We assume |V<sub>i</sub>| < 1/3.</p>
|
||||||
|
|
||||||
|
<p>Suppose that there is a number of competing unfinalized forks F1, F2 .. Fn. The validator's only possible actions are to (i) prepare a single <code>F_i</code> (if they prepare they will be slashed), and (ii) commit one or more <code>F_i</code>. Let <code>P(F_i)</code> be the probability that the validator believes that a given fork will be finalized (whether in this epoch or indirectly in a future one) conditional on that validator preparing on that fork. Let:</p>
|
||||||
|
|
||||||
|
<ul>
|
||||||
|
<li><code>L(e, F_i)</code> be the validator's private expectation of the number of epochs until a descendant of <code>F_i</code> gets prepares from two thirds of validators.</li>
|
||||||
|
</ul>
|
||||||
|
|
||||||
|
<p>The validator's expected return from preparing <code>F_i</code> is clearly <code>P(F_i) * D * NPP</code>. The validator can hence maximize revenues by going for the <code>F_i</code> with maximum probability of being finalized. This creates incentives for convergence. The validator's incentive for committing is made up of two components: (i) the reward <code>P(F_i) * D * NCP</code>, and (ii) an implied penalty <code>sum_{F_j: F_1 ... F_n, F_j != F_i} P(F_j) * NPP * L(e, F_j)</code> because if the validator commits on a fork that does not get adopted then they will be unable to prepare until two thirds of other validators prepare some future value. <code>L(e, F_j) >= 1</code>, so we can lower-bound the penalty with <code>(1 - P(F_i)) * D * NPP</code>. This suggests that validators will not commit a value unless they are at least <code>NPP / (NPP + NCP)</code> sure that it will be finalized.</p>
|
||||||
|
|
||||||
|
<h4>Coordinated Choice</h4>
|
||||||
|
|
||||||
|
<p>Any coalition of size equal to or greater than 1/3 of the total validator set can cause a safety or liveness failure. If they cause a safety failure, then they can get caught via the slashing conditions, and lose an amount of money equal to their entire security deposits. The trickier case is liveness failures.</p>
|
||||||
|
|
||||||
|
<p>The cheapest liveness failure to cause is for 1/3 of validators to continue preparing, but stop committing. In this case, they can delay finality by <code>d</code> epochs at a cost of <code>1/3 * TD * k / sqrt(TD) * 1/2 * sum(i = 2 ... d+1: log(i))</code> ~= <code>k * sqrt(TD) / 6 * ((d + 1) * log(d + 1) - (d + 1))</code>.</p>
|
||||||
|
|
||||||
|
<h3>Griefing Factor Analysis</h3>
|
||||||
|
|
||||||
|
<p>Another important kind of analysis to make in public economic protocols is the risk to honest validators. In general, if all validators are honest, and if network latency stays below the length of an epoch, then validators face zero risk beyond the usual risks of losing or accidentally divulging access to their private keys. In the case where malicious validators exist, we can analyze the risk to honest validators through <em>griefing factor analysis</em>.</p>
|
||||||
|
|
||||||
|
<p>We can approximately define the "griefing factor" as follows:</p>
|
||||||
|
|
||||||
|
<blockquote>
|
||||||
|
<p>A strategy used by a coalition in a given mechanism exhibits a griefing factor B if it can be shown that this strategy imposes a loss of B * x to those outside the coalition at the cost of a loss of x to those inside the coalition.</p>
|
||||||
|
</blockquote>
|
||||||
|
|
||||||
|
<p>Further:</p>
|
||||||
|
|
||||||
|
<blockquote>
|
||||||
|
<p>If all strategies that cause deviations from some given baseline state exhibit griefing factors <= some bound B, then we call B a griefing factor bound.</p>
|
||||||
|
</blockquote>
|
||||||
|
|
||||||
|
<p>A strategy that imposes a loss to outsiders either at no cost to a coalition, or to the benefit of a coalition, is said to have a griefing factor of infinity.</p>
|
||||||
|
|
||||||
|
<p>Fact:</p>
|
||||||
|
|
||||||
|
<blockquote>
|
||||||
|
<p>Proof of work blockchains have a griefing factor bound of infinity.</p>
|
||||||
|
</blockquote>
|
||||||
|
|
||||||
|
<p>Proof:</p>
|
||||||
|
|
||||||
|
<p>51% coalitions can double their revenue by refusing to build on blocks from all other miners, reducing the revenue of outside miners to zero. Due to selfish mining, griefing factor bounds are also infinity in all models that allow coalitions of size greater than ~0.2321 [cite], and even without selfish mining a miner can grief simply by mining with more hardware than the quantity that would maximize their profits.</p>
|
||||||
|
|
||||||
|
<p>Let us start off our griefing analysis by not taking into account validator churn, so all dynasties are identical. Because the equations involved are fractions of linear equations, we know that small churn will only lead to small changes in the results. In Casper, we can identify the following deviating strategies:</p>
|
||||||
|
|
||||||
|
<ol>
|
||||||
|
<li>Less than 1/3 of validators do not commit.</li>
|
||||||
|
<li>(Mirror image of 1) A censorship attack where 2/3 of validators block commits from less than 1/3 of validators.</li>
|
||||||
|
<li>Less than 1/3 of validators do not prepare.</li>
|
||||||
|
<li>(Mirror image of 3) A censorship attack where 2/3 of validators block prepares from less than 1/3 of validators.</li>
|
||||||
|
<li>More than 1/3 of validators do not commit.</li>
|
||||||
|
<li>(Mirror image of 5) A censorship attack where between 1/3 and 1/2 are blocked from committing (cannot be more because in the >1/2 case, the chain committed to by censorship victims will be viewed as winning)</li>
|
||||||
|
<li>More than 1/3 of validators do not prepare.</li>
|
||||||
|
<li>(Mirror image of 7) A censorship attack where between 1/3 and 1/2 are blocked from preparing.</li>
|
||||||
|
</ol>
|
||||||
|
|
||||||
|
<p>We will ignore (8), because we assume in our model that the underlying proposal mechanism (ie. proof of work) is majority-honest, and there is no way for validators to do this.</p>
|
||||||
|
|
||||||
|
<p>Let us now analyze the griefing factors:</p>
|
||||||
|
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<td> Attack </td> <td> Amount lost by attacker </td> <td> Amount lost by victims </td> <td> Griefing factor </td> <td> Notes </td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td> k < 1/3 non-commit </td> <td> NCP * k + NCCP * k<sup>2</sup></td> <td> NCCP * k * (1-k) </td> <td> NCCP / NCP </td>
|
||||||
|
<td> The griefing factor is maximized when k -> 0 </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
<tr>
|
||||||
|
<td> Censor k < 1/3 committers </td> <td> NCCP * k * (1-k) </td> <td> NCP * k + NCCP * k<sup>2</sup></td> <td> 1.5 * (NCP + NCCP / 3) / NCCP </td>
|
||||||
|
<td> The griefing factor is maximized when k -> 1/3 </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
<tr>
|
||||||
|
<td> k < 1/3 non-prepare </td> <td> NPP * k + NCCP * k<sup>2</sup></td> <td> NPCP * k * (1-k) </td> <td> NPCP / NPP </td>
|
||||||
|
<td> The griefing factor is maximized when k -> 0 </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
<tr>
|
||||||
|
<td> Censor k < 1/3 preparers </td> <td> NPCP * k * (1-k) </td> <td> NPP * k + NPCP * k<sup>2</sup> </td> <td> 1.5 * (NPP + NPCP / 3) / NPCP </td>
|
||||||
|
<td> The griefing factor is maximized when k -> 1/3 </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
<tr>
|
||||||
|
<td> k > 1/3 non-commit </td> <td> NFP * k + NCP * k + NCCP * k<sup>2</sup></td> <td> NFP * (1-k) + NCCP * k * (1-k)</td> <td>2 * (NFP + NCCP / 3) / (NFP + NCP + NCCP / 3)</td>
|
||||||
|
<td> The griefing factor is maximized when k = 1/3 </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
<tr>
|
||||||
|
<td> Censor k > 1/3 non-committers </td> <td> NFP * (1-k) + NCCP * k * (1-k) </td> <td> NFP * k + NCP * k + NCCP * k<sup>2</sup> </td> <td> 1 + NCCP / (NFP + NCP + NCCP / 2)</td>
|
||||||
|
<td> The griefing factor is maximized when k -> 1/2 </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
<tr>
|
||||||
|
<td> k > 1/3 non-prepare </td> <td> NFP * k + NCP * k + NPP * k + NPCP * k<sup>2</sup></td> <td> NFP * (1-k) + NCP * (1-k) + NPCP * k * (1-k)</td> <td>2 * (NFP + NCP + NPCP / 3) / (NFP + NCP + NPP + NPCP / 3)</td>
|
||||||
|
<td> The griefing factor is maximized when k = 1/3 </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
</table>
|
||||||
|
|
||||||
|
<p>There seems to be a three-dimensional space of optimal solutions with griefing factor bound 1.5, with constaints NCCP = NCP * 1.5 and NPCP = NPP * 1.5. One solution is:</p>
|
||||||
|
|
||||||
|
<p>NCP = 1/2 <br />
|
||||||
|
NCCP = 3/4 <br />
|
||||||
|
NPP = 2/3 <br />
|
||||||
|
NPCP = 1 <br />
|
||||||
|
NFP = 1 </p>
|
||||||
|
|
||||||
|
<p>The griefing factors are: (3/2, 3/2, 3/2, 3/2, 10/7, 7/5, 44/30)</p>
|
||||||
|
|
||||||
|
<p>However, we may want to voluntarily accept higher griefing factors against dominant coalitions in exchange for lower griefing factors against smaller coalitions, the reasoning being that this makes it easier to escape dominant attacking coalitions via a user-activated soft fork (see next section). In this case, an alternative solution is:</p>
|
||||||
|
|
||||||
|
<p>NCP = 1.5 <br />
|
||||||
|
NCCP = 1.5 <br />
|
||||||
|
NPP = 3.75 <br />
|
||||||
|
NPCP = 3.75 <br />
|
||||||
|
NFP = 1 </p>
|
||||||
|
|
||||||
|
<p>With griefing factors (1, 2, 1, 2, 1, 19/13, 1), a bound of 1.</p>
|
||||||
|
|
||||||
|
<p>Increasing the griefing factor bound for censoring coalitions to 3 introduces a solution:</p>
|
||||||
|
|
||||||
|
<p>NCP = 5 <br />
|
||||||
|
NCCP = 3 <br />
|
||||||
|
NPP = 26.667 <br />
|
||||||
|
NPCP = 16 <br />
|
||||||
|
NFP = 1 </p>
|
||||||
|
|
||||||
|
<p>With griefing factors (3/5, 3, 3/5, 3, 4/7, 7/5, 34/57), a bound of 3/5.</p>
|
||||||
|
|
||||||
|
<p>And increasing to 3 introduces </p>
|
||||||
|
|
||||||
|
<h3>Recovering from Coalition Attacks</h3>
|
||||||
|
|
||||||
|
<p>Suppose that there exists a coalition of size >= 1/3 (possibly even size >= 2/3) that engages in attacks of type (5), (6) or (7) above. This type of attack can be resolved in honest nodes' favor, but in many cases (especially those where the dishonest coalition is of size >= 1/2) this requires some out-of-band coordination between users, which can only partially be automated. This does require a synchrony assumption between validators and users, but one on the order of weeks (more precisely, the synchrony assumption must be on the same order as the amount of time that a >33% attack will take to resolve; resolution taking weeks is arguably acceptable because the prepetrators will lose a large portion of their deposits in this kind of attack).</p>
|
||||||
|
|
||||||
|
<p>Such an attack and resolution would proceed as follows. First, suppose that a validator with >= 1/3 of nodes simply stops committing, or logs out outright and stops committing and preparing. The two cases are alike so we can consider just the second.</p>
|
||||||
|
|
||||||
|
<p>The offline validator loses <code>(NCP + NPP + NPCP * 1/3 + NFP) * PENALTY_FACTOR</code> times their balance. Online validators lose <code>(NCP + NPCP * 1/3 + NFP) * PENALTY_FACTOR</code> times their balance. With the "griefing factor bound 2" settings, this gives a loss of 1.5 + 3.75 + 1.25 + 1 = 7.5 for the offline validator and a loss of 1.5 + 1.25 + 1 = 3.75 for online validators, so the offline validator's balance drains twice as quickly. Suppose that the original fraction of the offline validator is p > 1/3, and let t be the fraction of each online validator's balance remaining. Users need to wait until the balances decrease, to the point where <code>p * t**2 = 1/2 * (1 - p) * t</code>, or <code>t = (1-p) / 2p</code>. For example, if 40% of validators drop offline, then <code>t = 0.75</code>, and so online validators will lose 25% of their funds and offline validators will lose 43.75%.</p>
|
||||||
|
|
||||||
|
<p>Note that this real-time reduction of deposits does introduce a new consideration: if there are two conflicting checkpoints that finalize, the validator sets between the two checkpoints can now differ. In the most extreme case, this implies the possibility of two conflicting finalizing checkpoints where on one of the two checkpoints no deposits are lost. For example, consider the case of two finalized checkpoints C1 and C2, where C1 comes one epoch after the previous finalized checkpoint, but C2 comes long in the future, where <code>t = 1/2</code> (say, this is after three weeks). It's entirely possible for two thirds of the validator set in C1 to finalize C1, where the remaining one third is precisely the two thirds of the validator set in C2 that then finalizes C2.</p>
|
||||||
|
|
||||||
|
<p>[diagram]</p>
|
||||||
|
|
||||||
|
<p>This can be resolved with a synchrony assumption. If the node is constantly online, then it should refuse to accept C2 until three weeks have actually passed, and so as long as C1 can reach the node within three weeks there is no security risk (more precisely, latencies that are significant but below three weeks can reduce the amount of equivocation needed for double finalization, perhaps from 1/3 to 32.5% if latency is a day or 25% if latency is a week, though the exact figures depend on the exact formula used).</p>
|
||||||
|
|
||||||
|
<p>More formally, if C2 comes after C1, and the t values are t(C2) and t(C1), then the amount of equivocation required is <code>(2/3 * t(C2) + 2/3 * t(C1)) - t(C1)</code>, and inside of C1 <code>1 - t(C1)</code> would be lost due to the non-validation penalties - a total loss of <code>2/3 * t(C2) - 1/3 * t(C1) + 1 - t(C1)</code>, or <code>2/3 * t(C2) + 1 - 4/3 * t(C1)</code>. Regardless of <code>t(C2)</code>, this is clearly minimized when <code>t(C1) = 1</code>, so we have <code>2/3 * t(C2) - 1/3</code>. With the above synchrony assumption, we only need to be concerned about C2 if the distance is C1 and C2 is sufficiently small, and so we can specify a lower bound on <code>t(C2)</code>.</p>
|
||||||
|
|
||||||
|
<p>Now, let us consider the attacks where the censoring coalition is >= 1/2. Then, minority validators will refuse to build on chains that are censoring them, and so they will coordinate on their own chain. The result will be exactly the same as the result above: a majority chain and a minority chain, where under the rules of the protocol the majority chain will be able to finalize first, and where on the majority chain the victims will lose money faster than the attackers and so the attackers will be even stronger.</p>
|
||||||
|
|
||||||
|
<p>The asymmetry can be broken because users can manually implement a "user activated soft fork" where they refuse to accept the majority (attacking) chain, and so they can simply wait until the minority chain sheds deposits to the point where a checkpoint can be finalized by the non-colluding nodes. This coordination can be partially automated, as online nodes will be able to detect censorship, but it's impossible to make the automation perfect (as a perfect solution would violate impossibility results in distributed consensus); hence, a preferred solution is for nodes to give an alert if they believe the majority chain is attacking, and give the user an option of whether to continue with the majority chain or fork to the minority chain.</p>
|
||||||
|
|
||||||
|
<h3>Dealing with Failures in Proof of Work</h3>
|
||||||
|
|
||||||
|
<p>In this kind of design, the underlying chain is still generated by proof of work. However, there is much less need to worry about 51% attacks on the proof of work for several reasons.</p>
|
||||||
|
|
||||||
|
<p>There are three kinds of 51% attacks in proof of work:</p>
|
||||||
|
|
||||||
|
<ul>
|
||||||
|
<li><strong>After the fact finality reversion</strong> - make a chain longer than the existing main chain, reverting a large number of blocks at the end of the existing main chain that were thought to be finalized.</li>
|
||||||
|
<li><strong>Equivocation</strong> - create two "main chains" A and B that both appear long enough to be the main chain; convince one actor that A is finalized and another actor that B is finalized.</li>
|
||||||
|
<li><strong>Censorship</strong> - refuse to include blocks and transactions from other miners.</li>
|
||||||
|
</ul>
|
||||||
|
|
||||||
|
<p>Finality reversion is impossible outright for miners to carry out, as finality is defined by the finality gadget and not proof of work; this immediately eliminates the worst kind of 51% attack. Equivocation can be used to prevent finality by repeatedly creating multiple chains with different checkpoints for each epoch, so that validators never manage to put two thirds of their prepares behind a single one. Censorship can be used to prevent validators from being rewarded, along with the first-order consenquences of making the chain unusable.</p>
|
||||||
|
|
||||||
|
<p>If worse comes to worst, equivocation can be dealt with manually by having validators come together over an out-of-band communication channel to coordinate on finalizing checkpoints until a hard fork to replace the proof of work can be conducted. However, there is also another more automatable approach: validators can start ignoring checkpoints unless their proof of work meets a higher difficulty threshold. Suppose that malicious miners have an n:1 advantage against honest miners, and malicious miners need to create c competing checkpoints to reliably prevent convergence (say, c = 3, as if c = 2 then one of the two may easily get two thirds prepares by random chance). This will eventually lead to the situation where the malicious miners will attempt to create c admissible checkpoints and publish them simultaneously, and ~1 - c/n of the time they will succeed, but the other c/n of the time an honest miner will create a single checkpoint first, and the consensus will move forward. </p>
|
||||||
|
|
||||||
|
<p>Censorship can be dealt with by having validators refuse to prepare checkpoints that do not include values that they believe should have been prepared.</p>
|
||||||
|
|
||||||
|
<h3>Discouragement Attacks</h3>
|
||||||
|
|
||||||
|
<p>Perhaps the most difficult kind of attack to deal with in this algorithm is a "discouragement attack". This attack happens in two stages. First, an attacker engages in a medium-grade liveness degradation attack, with the main goal of reducing the rewards for honest validators to below zero, or at least to below their capital lockup costs. Then, the attacker engages in more serious attacks on liveness or safety against a much smaller pool of honest validators. A discouragement attack requires the attacker to have an amount of deposits equal to 1/3 of the original total deposit size, but allows them to trigger liveness and safety failures much more cheaply.</p>
|
||||||
|
|
||||||
|
<p>It is worth noting that proof of work is extremely vulnerable to discouragement attacks: assuming a competitive market where miners have low profits, a selfish mining attack can quickly force other miners offline, at which point the miner can engage in a 51% attack. Hence, even if our treatment of discouragement attacks is not fully satisfactory, it arguably still fares substantially better than other protocols.</p>
|
||||||
|
|
||||||
|
<p>Along with minimizing griefing factors, we can mitigate discouragement attacks using another strategy: those who are currently non-validators can coordinate on joining the validator set en masse, overwhelming the attacker to the point that their share of the total validator set is less than 1/3 and their griefing is no longer effective. We expect many to be willing to join altruistically, but we can also recycle a portion of penalties into future rewards, thereby temporarily increasing the incentive for new joiners.</p>
|
||||||
|
|
@ -0,0 +1,324 @@
|
||||||
|
### Casper The Friendly Finality Gadget
|
||||||
|
|
||||||
|
This document describes a candidate design for the first implementation of Casper proof of stake on Ethereum. The proposal aims to achieve the key goals of deposit-based proof of stake including highly secure finality and low-cost consensus, but do so in a way that can be applied with minimal disruption to existing chains, including the current Ethereum proof of work chain. We describe the workings of the algorithm, show safety and liveness in a partially-synchronous fault-tolerance-theoretic model, and then proceed to describe the various considerations involving game-theoretic incentives, as well as how the system can automatically recover from >1/3 of nodes dropping offline, and with the use of lightweight out-of-band coordination assumptions, recover from various forms of 51% attacks. We will describe the algorithm in stages with increasing complexity, in order to show the core ideas first, and then bring in features such as validator set rotation and economic incentivization.
|
||||||
|
|
||||||
|
### Background
|
||||||
|
|
||||||
|
Proof of stake has for a long time been viewed as a highly promising, but controversial, alternative to proof of work as a way of securing cryptoeconomic public blockchain consensus. Whereas proof of work measures economic consensus by measuring the quantity of computational resources that have been expended to "back" a particular state and history, proof of stake in simplest form seeks to replace physical mining with CPUs, GPUs and ASICs with "virtual mining" [cite], where economic consensus is measured by the economic resources inside the system that are committing to a given state and history.
|
||||||
|
|
||||||
|
However, early versions of proof of stake suffer from a flaw that is often called "nothing at stake" [cite], which states that if one naively builds a proof of stake algorithm by simply copying the intuitions and algorithms from proof of work, then the result is an algorithm where, in the event of a disagreement between whether to choose chain A or chain B, it is in every rational participant's interest to choose both. Unlike proof of work, where resources _on the outside_ can be applied to either chain A or chain B but not both, in naive proof of stake the very fact of a chain split means that there is also a temporary split of the ledger of on-chain economic resources, and so a validator can use their copy of the resources on chain A to back chain A and a copy of their resources on chain B to back chain B.
|
||||||
|
|
||||||
|
PoW
|
||||||
|
<img src="https://raw.githubusercontent.com/vbuterin/diagrams/master/powsec.png" width="400px"></img>
|
||||||
|
PoS
|
||||||
|
<img src="https://raw.githubusercontent.com/vbuterin/diagrams/master/possec.png" width="400px"></img>
|
||||||
|
|
||||||
|
Casper builds on a tradition that was started with the description of [Slasher](#) in early 2014, which attempts to explicitly detect such "equivocation" (a common Byzantine-fault-tolerance-theoretic term for the act of sending two messages that contradict each other, in this case by simultaneously supporting two conflicting forks), and economically penalize validators that are caught engaging in such behavior in order to discourage it.
|
||||||
|
|
||||||
|
<img src="https://raw.githubusercontent.com/vbuterin/diagrams/master/slasher1sec.png" width="400px"></img>
|
||||||
|
|
||||||
|
This solves nothing at stake (at the cost of an extremely weak synchrony assumption that will be discussed later), and ensures that such proof of stake algorithms can be at least as secure as proof of work. However, we can go further. It was soon discovered by Vlad Zamfir that consensus algorithms based on penalties could be made vastly more secure than consensus algorithms that are purely based on rewards, because there is an inherent asymmetry between the two. Whereas rewards are inherently limited in the size of the incentive that they offer, as every reward paid out must be paid out by the protocol, penalties can theoretically go much higher, potentially even all the way up to the entire pool of capital that the participant is participating in the proof of stake mechanism with.
|
||||||
|
|
||||||
|
This allows for the introduction of a notion of _economic finality_:
|
||||||
|
|
||||||
|
> A block, state or any constraint on the set of admissible histories can be considered _finalized_ if it can be shown that if any incompatible block, state or constraint is also finalized (eg. two different blocks at the same height) then there exists evidence that can be used to penalize the parties at fault by some amount $X. This value X is called the _cryptoeconomic security margin_ of the finality mechanism.
|
||||||
|
|
||||||
|
However, such strict forms of penalty-based proof of stake run into another risk: the possibility of "getting stuck":
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
A poorly designed algorithm could lead to a situation where it is not possible for any new block to be finalized, without at least some participants taking some action that would lead them to incur the penalty. Making an algorithm that can provide genuine finality, and that also avoids the possibility of getting stuck under all but the most exceptional circumstances, is a difficult challenge - but one that maps very well to problems that have already been studied for a long time under the aegis of Byzantine fault tolerance theory.
|
||||||
|
|
||||||
|
Algorithms such as PBFT, Paxos and HoneyBadger BFT [cite * 3] all try to achieve a similar goal, of achieving "consensus" between some group of nodes (sometimes called "processes"). An early attempt at defining the problem was through the Byzantine general's problem, where a group of generals are trying to coordinate on a specific plan for how to attack a city, but some of the generals may be traitors. The two goals are:
|
||||||
|
|
||||||
|
A. All loyal generals decide upon the same plan of action.
|
||||||
|
B. A small number of traitors cannot cause the loyal generals to adopt a bad plan. [cite Lamport 1982]
|
||||||
|
|
||||||
|
In a consensus algorithm implemented in real life, the "plan of action" to be decided on is that of which operations are to be processed in what order.
|
||||||
|
|
||||||
|
In our case, the goal is not just to have one round of consensus to agree on a single value, but rather have ongoing rounds of consensus on an ever-growing chain. In a blockchain, every block contains the hash of the previous block, and so it is inherently linked to a history containing ancestor blocks going all the way back to some "genesis block" that was agreed to as one of the parameters of the protocol. Coming to consensus on a block inherently involves coming to consensus on all of its ancestors. Hence, the consensus algorithm must avoid not just coming to consensus on two conflicting blocks during one period, but rather it must also avoid coming to consensus on a block when it has already come to consensus on a block that conflicts with one of the block's ancestors.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
We will start off by presenting "Minimal Slashing Conditions", a mechanism that has this property, and that can also arguably be used in other contexts as a simpler alternative to PBFT.
|
||||||
|
|
||||||
|
### Minimal Slashing Conditions
|
||||||
|
|
||||||
|
This algorithm assumes the existence of an underlying **proposal mechanism**, which creates a chain of blocks which is constantly growing, and where given a set of blocks there is a way to deterministically calculate what is the "tip" of the chain. The chain may grow in a perfectly orderly fashion, with one block being added to the tip every few seconds, or it may sometimes have "forks" where a given parent block has two children and one of the two children is eventually abandoned, or in the worst case the chain may grow highly chaotically, with multiple long-running branches with the identity of the tip constantly switching from one chain to another.
|
||||||
|
|
||||||
|
The proposal mechanism working with a relatively high level of quality is not necessary for safety; provided more than 2/3 of nodes correctly follow the protocol conflicting checkpoints will not be finalized no matter how poorly the proposal mechanism behaves. However, if the proposal mechanism behaves very poorly, this may prevent liveness.
|
||||||
|
|
||||||
|
The proposal mechanism is deliberately kept abstract; this can be a dictator, it can be a round-robin scheme between the participants in the consensus, or, as in our case with hybrid Casper, it will be the original proof of work chain.
|
||||||
|
|
||||||
|
Every hundredth block in the chain is called a **checkpoint**, and the period between two checkpoints is called an **epoch**. We assume the existence of a set of **validators** V<sub>1</sub> ... V<sub>n</sub>, with sizes S(V<sub>1</sub>) ... S(V<sub>n</sub>); in hybrid proof of stake each of these validators must have put down a deposit, and the amount of ETH in that deposit becomes their size.
|
||||||
|
|
||||||
|
Validators have the ability to send two classes of messages:
|
||||||
|
|
||||||
|
[PREPARE, epoch, hash, epoch_source, hash_source]
|
||||||
|
[COMMIT, epoch, hash]
|
||||||
|
|
||||||
|
The intention is that during epoch `n`, validators wait for the proposal mechanism to create a checkpoint during epoch `n` (say, with hash `H`), and then create a PREPARE message for epoch `n` and hash `H`. The `epoch_souce` and `hash_source` values should refer to the most recent (in terms of epoch number) checkpoint that they know about that has received prepares from a set of validators PREPSET where `sum_{v in PREPSET} S(V) >= sum_{v in ALL_VALIDATORS} S(V) * 2/3` (hereinafter, we will refer to a set which has this property as "at least two thirds of validators"; any reference to a fraction of the validator set should be read as being weighted by size). If/when at least two thirds of validators create a PREPARE for `n` and `H` with the same `epoch_source` and `hash_source`, validators should then send a message to COMMIT `n` and `H`. If two thirds of validators do this, the checkpoint is considered finalized.
|
||||||
|
|
||||||
|
Although we say that validators "should" follow the above set of rules, in many circumstances there is no way to enforce that they are in fact doing so. For example, consider a case where the proposal mechanism forks and creates two competing checkpoints at epoch `n`, C1 and C2. Suppose that a validator sees C1 five seconds before C2. According to the above rules, the validator _should_ prepare on C1. However, if the validator prepares on C2, this cannot be detected, because for all we know the message containing C1 _could_ have been delayed by six seconds en route to that validator's computer and so the validator could have seen C2 first.
|
||||||
|
|
||||||
|
However, what we _can_ do is identify a few specific cases where there is clear evidence that a validator acted incorrectly, and in these cases penalize the validator heavily - in fact, we can even go so far as to take away their entire deposit.
|
||||||
|
|
||||||
|
We can do this by defining a set of "slashing conditions", where if any validator triggers one of the four conditions they will lose their entire deposit. The conditions are as follows:
|
||||||
|
|
||||||
|
[copy from medium post]
|
||||||
|
|
||||||
|
We would like to prove two properties about this mechanism:
|
||||||
|
|
||||||
|
1. **Accountable safety** : if two conflicting hashes get finalized, then it must be provably true that at least 1/3 of validators violated some slashing condition.
|
||||||
|
2. **Plausible liveness**: unless at least 1/3 of validators violated some slashing condition, there must exist a set of messages that 2/3 of validators can send which finalize some new hash without violating some slashing condition.
|
||||||
|
|
||||||
|
Details of a machine-verifiable proof in Isabelle can be [found here](https://medium.com/@pirapira/formal-methods-on-some-pos-stuff-e309775c2ab8). A proof sketch is as follows:
|
||||||
|
|
||||||
|
Suppose that two conflicting hashes C1 and C2 get finalized. This means that in some epoch e1, C1 has 2/3 prepares and 2/3 commits, and in some epoch e2, C2 has 2/3 prepares and 2/3 commits (if either of those sets of 2/3 prepares were missing, 2/3 of validators would have violated `PREPARE_REQ`).. First, consider the easy case where e1 = e2. Then, 2/3 prepares on C1 and 2/3 prepares on C2 require 1/3 of validators to have violated `NO_DBL_PREPARE`.
|
||||||
|
|
||||||
|
Now, without loss of generality, consider the case where e2 > e1. By `PREPARE_REQ` the 2/3 prepares on C2 imply 2/3 prepares during some previous epoch e2' < e2. This in turn implies 2/3 prepares during some epoch e2'', and so forth until one of two terminating cases:
|
||||||
|
|
||||||
|
(i) e2\* = e1. Here, we have 2/3 prepares on C1, and 2/3 prepares on some ancestor of C2 which is not C1, and so 1/3 get slashed by `NO_DBL_PREPARE`
|
||||||
|
(ii) e2\* < e1. Here, we have 2/3 prepares with `epoch > e1` and `epoch_source < e1`, as well as 2/3 commits with `epoch = e1`. Hence, at least 1/3 of the preparers must have violated `PREPARE_COMMIT_CONSISTENCY`
|
||||||
|
|
||||||
|
Plausible liveness can be proven even more easily. Suppose that (i) P is the highest epoch where there are 2/3 prepares, and (ii) M is the highest epoch when any message has been sent. By (i) there were no honest commits with epoch above P, and so 2/3 of validators can safely prepare any value with epoch M+1, and epoch source P. They can then safely commit that value.
|
||||||
|
|
||||||
|
### Hybrid fork choice rule
|
||||||
|
|
||||||
|
The mechanism described above ensures _plausible liveness_; however, it does not ensure _actual liveness_ - that is, while the mechanism cannot get stuck in the strict sense, it could still enter a scenario where the proposal mechanism gets into a state where it never ends up creating a checkpoint that could get finalized.
|
||||||
|
|
||||||
|
Here is one possible example:
|
||||||
|
|
||||||
|
<img src="https://cdn-images-1.medium.com/max/800/1*IhXmzZG9toAs3oedZX0spg.jpeg" width="400px"></img>
|
||||||
|
|
||||||
|
In this case, HASH1 or any descendant thereof cannot be finalized without slashing 1/6 of validators. However, miners on a proof of work chain would interpret HASH1 as the head and start mining descendants of it. In fact, when *any* checkpoint gets k > 1/3 commits, no conflicting checkpoint can get finalized without `k - 1/3` of validators getting slashed.
|
||||||
|
|
||||||
|
This necessitates modifying the fork choice rule used by participants in the underlying proposal mechanism (as well as users and validators): instead of blindly following a longest-chain rule, there needs to be an overriding rule that (i) finalized checkpoints are favored, and (ii) when there are no further finalized checkpoints, checkpoints with more (justified) commits are favored.
|
||||||
|
|
||||||
|
One complete description of such a rule would be:
|
||||||
|
|
||||||
|
1. Start with HEAD equal to the genesis of the chain.
|
||||||
|
2. Select the descendant checkpoint of HEAD with the most commits (only checkpoints with 2/3 prepares are admissible)
|
||||||
|
3. Repeat (2) until no descendant with commits exists.
|
||||||
|
4. Choose the longest proof of work chain from there.
|
||||||
|
|
||||||
|
The commit-following part of this rule can be viewed in some ways as mirroring the "greegy heaviest observed subtree" (GHOST) rule that has been proposed for proof of work chains. The symmetry is this: in GHOST, a node starts with the head at the genesis, then begins to move forward down the chain, and if it encounters a block with multiple children then it chooses the child that has the larger quantity of work built on top of it (including the child block itself and its descendants). Here, we follow a similar approach, except we repeatedly seek the child that comes the closest to achieving finality. A checkpoint is implicitly finalized if any of its descendants are finalized, and so we need to look at descendants and not just direct children. Finalizing a checkpoint requires 2/3 commits within a single epoch, and so we do not try to sum up commits across epochs and instead simply take the maximum.
|
||||||
|
|
||||||
|
### Adding Dynamic Validator Sets
|
||||||
|
|
||||||
|
The above assumes that there is a single set of validators that never changes. In reality, however, we want validators to be able to join and leave.
|
||||||
|
|
||||||
|
### Economic Fundamentals
|
||||||
|
|
||||||
|
The fault-tolerance-theoretic assumptions made so far simply assume that more than two thirds of every validator set is not willing to lose theire entire deposits, and given this assumption we can show safety. However, we must also show how the algorithm incentivizes liveness, and so so under several different sets of assumptions. We analyze the proof of stake component under both an uncoordinated choice model and a coordinated choice model. For now we assume that the underlying proof of work blockchain simply works, and ask our readers to accept this in light of uncoordinated choice modeling [cite] and empirical observations that coordinated attacks on proof of work have been rare so far, though in a later section we will discuss how validators can cooperate to overcome 51% attacks against the underlying proof of work layer.
|
||||||
|
|
||||||
|
### Protocol utility function
|
||||||
|
|
||||||
|
We will start off by specifying a "protocol utility function", a function which can be computed on any chain and which outputs a value that represents the "quality" of the chain. A unit decrease in protocol utility should be understood to represent a unit decrease in user satisfaction; our main objective is to maximize expected protocol utility.
|
||||||
|
|
||||||
|
We define protocol utility as follows:
|
||||||
|
|
||||||
|
sum_{block i = 1 ... n} -ln(i - LFE(i)) + c - M * SF_
|
||||||
|
|
||||||
|
Where:
|
||||||
|
|
||||||
|
* LFE(i) refers to the last epoch in the chain before block i that was finalized (in an optimally running chain, this is always i-1)
|
||||||
|
* SF = 1 if a safety failure was detected in the most recent epoch, as defined by 1/3 of validators getting slashed, otherwise 0
|
||||||
|
* c is the portion of commits in the current epoch
|
||||||
|
* M is a (very large) constant
|
||||||
|
|
||||||
|
Note that there is no single principled way to say what the protocol utility is; this is a question that ultimately rests on the values of the users of the system. However, we can defend the reasoning behind each component in the above formula.
|
||||||
|
|
||||||
|
The -M * SF term is self-explanatory; safety failures are very bad, as it means that events that appear to have been finalized, and that users may be relying on being finalized, suddenly become unfinalized. The -ln(i - LFE(i)) term is more complicated. What is it saying is that the amount of pain that users feel from having to wait `k` epochs for their transaction to be finalized is logarithmic in `k`. This can be justified inuitively: the difference between finality in 1 minute and 2 minutes feels similar in size to the difference between 1 hour and 2 hours. Another approach is to look at the possible set of blockchain applications, ranging from running games on them at the 100-1000 millisecond level, to retail payments at the 1-10 second level, other kinds of payments that currently take 1-10 minutes, and large institutional settlements that can take days, and see that they are roughly logarithmically distributed on the scale of the longest confirmation time that they could reasonably accept. The separate `c` term is there to show that even if a given epoch does not finalize, commits can still provide value, as a smaller number of commits on a given block can still make it harder to finalize competing blocks.
|
||||||
|
|
||||||
|
### Incentives
|
||||||
|
|
||||||
|
We define the full set of incentives that we assign to validators in any given epoch as follows.
|
||||||
|
|
||||||
|
From the point of view of the state in which the incentives are being calculated, let us assume:
|
||||||
|
|
||||||
|
* `e` is the epoch number
|
||||||
|
* `H` is the hash of the most recent checkpoint block
|
||||||
|
* `H_s` is the most recent justified checkpoint (ie. checkpoint with prepares from two thirds of the previous and current validator sets) that the state knows about
|
||||||
|
* `k` is a constant
|
||||||
|
* `TD` is the total size of deposits
|
||||||
|
* `LFE(e)` is the last finalized epoch
|
||||||
|
* `D` is a given validator's deposit size
|
||||||
|
|
||||||
|
During any epoch, define `BASE_INTEREST = D * k / sqrt(TD)` and `PENALTY_FACTOR = D * k / sqrt(TD) * log(1 + e - LFE(e))`. Abbreviate:
|
||||||
|
|
||||||
|
* `NCP` = non-commit penalty
|
||||||
|
* `NFP` = non-finality penalty
|
||||||
|
* `NPP` = non-prepare penalty
|
||||||
|
* `NCCP` = per-non-commit collective penalty
|
||||||
|
* `NPCP` = per-non-prepare collective penalty
|
||||||
|
|
||||||
|
Assume all references to the five above variables in the remaining section are actually referring to `NCP * PENALTY_FACTOR`, `NFP * PENALTY_FACTOR`, etc.
|
||||||
|
|
||||||
|
We define the penalties as follows:
|
||||||
|
|
||||||
|
* If the epoch is not finalized, all validators pay `NFP`
|
||||||
|
* All non-committing validators pay `NCP`. Waived if 2/3 prepares are not found (ie. validators cannot legally commit).
|
||||||
|
* All non-preparing validators pay `NPP`
|
||||||
|
* Suppose `cp` is the minimal fraction of validators between the two validator sets that commits (eg. if 80% of the validators in the current dynasty commit and 68% of the validators in the previous dynasty do, `cp = 0.68`). All validators pay `NCCP * (1 - cp)`. Waived if 2/3 prepares are not found (ie. validators cannot legally commit).
|
||||||
|
* Suppose `pp` is the minimal fraction of validators between the two validator sets that prepares. All validators pay `NPCP * (1-pp)`
|
||||||
|
|
||||||
|
#### Uncoordinated Choice
|
||||||
|
|
||||||
|
In an uncoordinated choice model, we assume that there is a validator set V<sub>1</sub> ... V<sub>n</sub>, with deposit sizes |V<sub>1</sub>| ... |V<sub>n</sub>|, and each validator acts independently according to their own incentives. We assume |V<sub>i</sub>| < 1/3.
|
||||||
|
|
||||||
|
Suppose that there is a number of competing unfinalized forks F1, F2 .. Fn. The validator's only possible actions are to (i) prepare a single `F_i` (if they prepare they will be slashed), and (ii) commit one or more `F_i`. Let `P(F_i)` be the probability that the validator believes that a given fork will be finalized (whether in this epoch or indirectly in a future one) conditional on that validator preparing on that fork. Let:
|
||||||
|
|
||||||
|
* `L(e, F_i)` be the validator's private expectation of the number of epochs until a descendant of `F_i` gets prepares from two thirds of validators.
|
||||||
|
|
||||||
|
The validator's expected return from preparing `F_i` is clearly `P(F_i) * D * NPP`. The validator can hence maximize revenues by going for the `F_i` with maximum probability of being finalized. This creates incentives for convergence. The validator's incentive for committing is made up of two components: (i) the reward `P(F_i) * D * NCP`, and (ii) an implied penalty `sum_{F_j: F_1 ... F_n, F_j != F_i} P(F_j) * NPP * L(e, F_j)` because if the validator commits on a fork that does not get adopted then they will be unable to prepare until two thirds of other validators prepare some future value. `L(e, F_j) >= 1`, so we can lower-bound the penalty with `(1 - P(F_i)) * D * NPP`. This suggests that validators will not commit a value unless they are at least `NPP / (NPP + NCP)` sure that it will be finalized.
|
||||||
|
|
||||||
|
#### Coordinated Choice
|
||||||
|
|
||||||
|
Any coalition of size equal to or greater than 1/3 of the total validator set can cause a safety or liveness failure. If they cause a safety failure, then they can get caught via the slashing conditions, and lose an amount of money equal to their entire security deposits. The trickier case is liveness failures.
|
||||||
|
|
||||||
|
The cheapest liveness failure to cause is for 1/3 of validators to continue preparing, but stop committing. In this case, they can delay finality by `d` epochs at a cost of `1/3 * TD * k / sqrt(TD) * 1/2 * sum(i = 2 ... d+1: log(i))` ~= `k * sqrt(TD) / 6 * ((d + 1) * log(d + 1) - (d + 1))`.
|
||||||
|
|
||||||
|
### Griefing Factor Analysis
|
||||||
|
|
||||||
|
Another important kind of analysis to make in public economic protocols is the risk to honest validators. In general, if all validators are honest, and if network latency stays below the length of an epoch, then validators face zero risk beyond the usual risks of losing or accidentally divulging access to their private keys. In the case where malicious validators exist, we can analyze the risk to honest validators through _griefing factor analysis_.
|
||||||
|
|
||||||
|
We can approximately define the "griefing factor" as follows:
|
||||||
|
|
||||||
|
> A strategy used by a coalition in a given mechanism exhibits a griefing factor B if it can be shown that this strategy imposes a loss of B * x to those outside the coalition at the cost of a loss of x to those inside the coalition.
|
||||||
|
|
||||||
|
Further:
|
||||||
|
|
||||||
|
> If all strategies that cause deviations from some given baseline state exhibit griefing factors <= some bound B, then we call B a griefing factor bound.
|
||||||
|
|
||||||
|
A strategy that imposes a loss to outsiders either at no cost to a coalition, or to the benefit of a coalition, is said to have a griefing factor of infinity.
|
||||||
|
|
||||||
|
Fact:
|
||||||
|
|
||||||
|
> Proof of work blockchains have a griefing factor bound of infinity.
|
||||||
|
|
||||||
|
Proof:
|
||||||
|
|
||||||
|
51% coalitions can double their revenue by refusing to build on blocks from all other miners, reducing the revenue of outside miners to zero. Due to selfish mining, griefing factor bounds are also infinity in all models that allow coalitions of size greater than ~0.2321 [cite], and even without selfish mining a miner can grief simply by mining with more hardware than the quantity that would maximize their profits.
|
||||||
|
|
||||||
|
Let us start off our griefing analysis by not taking into account validator churn, so all dynasties are identical. Because the equations involved are fractions of linear equations, we know that small churn will only lead to small changes in the results. In Casper, we can identify the following deviating strategies:
|
||||||
|
|
||||||
|
1. Less than 1/3 of validators do not commit.
|
||||||
|
2. (Mirror image of 1) A censorship attack where 2/3 of validators block commits from less than 1/3 of validators.
|
||||||
|
3. Less than 1/3 of validators do not prepare.
|
||||||
|
4. (Mirror image of 3) A censorship attack where 2/3 of validators block prepares from less than 1/3 of validators.
|
||||||
|
5. More than 1/3 of validators do not commit.
|
||||||
|
6. (Mirror image of 5) A censorship attack where between 1/3 and 1/2 are blocked from committing (cannot be more because in the >1/2 case, the chain committed to by censorship victims will be viewed as winning)
|
||||||
|
7. More than 1/3 of validators do not prepare.
|
||||||
|
8. (Mirror image of 7) A censorship attack where between 1/3 and 1/2 are blocked from preparing.
|
||||||
|
|
||||||
|
We will ignore (8), because we assume in our model that the underlying proposal mechanism (ie. proof of work) is majority-honest, and there is no way for validators to do this.
|
||||||
|
|
||||||
|
Let us now analyze the griefing factors:
|
||||||
|
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<td> Attack </td> <td> Amount lost by attacker </td> <td> Amount lost by victims </td> <td> Griefing factor </td> <td> Notes </td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td> k < 1/3 non-commit </td> <td> NCP * k + NCCP * k<sup>2</sup></td> <td> NCCP * k * (1-k) </td> <td> NCCP / NCP </td>
|
||||||
|
<td> The griefing factor is maximized when k -> 0 </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
<tr>
|
||||||
|
<td> Censor k < 1/3 committers </td> <td> NCCP * k * (1-k) </td> <td> NCP * k + NCCP * k<sup>2</sup></td> <td> 1.5 * (NCP + NCCP / 3) / NCCP </td>
|
||||||
|
<td> The griefing factor is maximized when k -> 1/3 </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
<tr>
|
||||||
|
<td> k < 1/3 non-prepare </td> <td> NPP * k + NCCP * k<sup>2</sup></td> <td> NPCP * k * (1-k) </td> <td> NPCP / NPP </td>
|
||||||
|
<td> The griefing factor is maximized when k -> 0 </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
<tr>
|
||||||
|
<td> Censor k < 1/3 preparers </td> <td> NPCP * k * (1-k) </td> <td> NPP * k + NPCP * k<sup>2</sup> </td> <td> 1.5 * (NPP + NPCP / 3) / NPCP </td>
|
||||||
|
<td> The griefing factor is maximized when k -> 1/3 </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
<tr>
|
||||||
|
<td> k > 1/3 non-commit </td> <td> NFP * k + NCP * k + NCCP * k<sup>2</sup></td> <td> NFP * (1-k) + NCCP * k * (1-k)</td> <td>2 * (NFP + NCCP / 3) / (NFP + NCP + NCCP / 3)</td>
|
||||||
|
<td> The griefing factor is maximized when k = 1/3 </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
<tr>
|
||||||
|
<td> Censor k > 1/3 non-committers </td> <td> NFP * (1-k) + NCCP * k * (1-k) </td> <td> NFP * k + NCP * k + NCCP * k<sup>2</sup> </td> <td> max(1 + NCCP / (NFP + NCP + NCCP / 2), (NFP + NCP + NCCP / 3) / (NFP + NCCP / 3) / 2)</td>
|
||||||
|
<td> The griefing factor is maximized at either k -> 1/2, or k -> 1/3. </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
<tr>
|
||||||
|
<td> k > 1/3 non-prepare </td> <td> NFP * k + NPP * k + NPCP * k<sup>2</sup></td> <td> NFP * (1-k) + NPCP * k * (1-k)</td> <td>2 * (NFP + NPCP / 3) / (NFP + NPP + NPCP / 3)</td>
|
||||||
|
<td> The griefing factor is maximized when k = 1/3 </td>
|
||||||
|
</tr>
|
||||||
|
|
||||||
|
</table>
|
||||||
|
|
||||||
|
There seems to be a three-dimensional space of optimal solutions with griefing factor bound 1.5, with constaints NCCP = NCP * 1.5 and NPCP = NPP * 1.5. One solution is:
|
||||||
|
|
||||||
|
NCP = 1/2
|
||||||
|
NCCP = 3/4
|
||||||
|
NPP = 1/2
|
||||||
|
NPCP = 3/4
|
||||||
|
NFP = 1
|
||||||
|
|
||||||
|
The griefing factors are: (3/2, 3/2, 3/2, 3/2, 10/7, 7/5, 10/7)
|
||||||
|
|
||||||
|
However, we may want to voluntarily accept higher griefing factors against dominant coalitions in exchange for lower griefing factors against smaller coalitions, the reasoning being that this makes it easier to escape dominant attacking coalitions via a user-activated soft fork (see next section). In this case, an alternative solution is:
|
||||||
|
|
||||||
|
NCP = 3/2
|
||||||
|
NCCP = 3/2
|
||||||
|
NPP = 3/2
|
||||||
|
NPCP = 3/2
|
||||||
|
NFP = 1
|
||||||
|
|
||||||
|
With griefing factors (1, 2, 1, 2, 1, 19/13, 1), a bound of 1.
|
||||||
|
|
||||||
|
There are other solutions; for example, (3, 3, 3, 3, 1) is interesting because it reduces the griefing factors for 1/3 coalitions that prevent finality to 0.8, and (1, 1, 1, 1, 0) reduces the griefing factor for all <50% finality-preventing coalitions to 0.5, at the cost of allowing coalitions of size > 50% to censor at griefing factors between 5/3 and 2. More generally, if we allow censoring coalitions a griefing factor of k, we can reduce the griefing factor for minority coalitions to 3 / (2 * k - 1).
|
||||||
|
|
||||||
|
### Recovering from Coalition Attacks
|
||||||
|
|
||||||
|
Suppose that there exists a coalition of size >= 1/3 (possibly even size >= 2/3) that engages in attacks of type (5), (6) or (7) above. This type of attack can be resolved in honest nodes' favor, but in many cases (especially those where the dishonest coalition is of size >= 1/2) this requires some out-of-band coordination between users, which can only partially be automated. This does require a synchrony assumption between validators and users, but one on the order of weeks (more precisely, the synchrony assumption must be on the same order as the amount of time that a >33% attack will take to resolve; resolution taking weeks is arguably acceptable because the prepetrators will lose a large portion of their deposits in this kind of attack).
|
||||||
|
|
||||||
|
Such an attack and resolution would proceed as follows. First, suppose that a validator with >= 1/3 of nodes simply stops committing, or logs out outright and stops committing and preparing. The two cases are alike so we can consider just the second.
|
||||||
|
|
||||||
|
The offline validator loses `(NCP + NPP + NPCP * 1/3 + NFP) * PENALTY_FACTOR` times their balance. Online validators lose `(NCP + NPCP * 1/3 + NFP) * PENALTY_FACTOR` times their balance. With the "griefing factor bound 2" settings, this gives a loss of 1.5 + 3.75 + 1.25 + 1 = 7.5 for the offline validator and a loss of 1.5 + 1.25 + 1 = 3.75 for online validators, so the offline validator's balance drains twice as quickly. Suppose that the original fraction of the offline validator is p > 1/3, and let t be the fraction of each online validator's balance remaining. Users need to wait until the balances decrease, to the point where `p * t**2 = 1/2 * (1 - p) * t`, or `t = (1-p) / 2p`. For example, if 40% of validators drop offline, then `t = 0.75`, and so online validators will lose 25% of their funds and offline validators will lose 43.75%.
|
||||||
|
|
||||||
|
Note that this real-time reduction of deposits does introduce a new consideration: if there are two conflicting checkpoints that finalize, the validator sets between the two checkpoints can now differ. In the most extreme case, this implies the possibility of two conflicting finalizing checkpoints where on one of the two checkpoints no deposits are lost. For example, consider the case of two finalized checkpoints C1 and C2, where C1 comes one epoch after the previous finalized checkpoint, but C2 comes long in the future, where `t = 1/2` (say, this is after three weeks). It's entirely possible for two thirds of the validator set in C1 to finalize C1, where the remaining one third is precisely the two thirds of the validator set in C2 that then finalizes C2.
|
||||||
|
|
||||||
|
[diagram]
|
||||||
|
|
||||||
|
This can be resolved with a synchrony assumption. If the node is constantly online, then it should refuse to accept C2 until three weeks have actually passed, and so as long as C1 can reach the node within three weeks there is no security risk (more precisely, latencies that are significant but below three weeks can reduce the amount of equivocation needed for double finalization, perhaps from 1/3 to 32.5% if latency is a day or 25% if latency is a week, though the exact figures depend on the exact formula used).
|
||||||
|
|
||||||
|
More formally, if C2 comes after C1, and the t values are t(C2) and t(C1), then the amount of equivocation required is `(2/3 * t(C2) + 2/3 * t(C1)) - t(C1)`, and inside of C1 `1 - t(C1)` would be lost due to the non-validation penalties - a total loss of `2/3 * t(C2) - 1/3 * t(C1) + 1 - t(C1)`, or `2/3 * t(C2) + 1 - 4/3 * t(C1)`. Regardless of `t(C2)`, this is clearly minimized when `t(C1) = 1`, so we have `2/3 * t(C2) - 1/3`. With the above synchrony assumption, we only need to be concerned about C2 if the distance is C1 and C2 is sufficiently small, and so we can specify a lower bound on `t(C2)`.
|
||||||
|
|
||||||
|
Now, let us consider the attacks where the censoring coalition is >= 1/2. Then, minority validators will refuse to build on chains that are censoring them, and so they will coordinate on their own chain. The result will be exactly the same as the result above: a majority chain and a minority chain, where under the rules of the protocol the majority chain will be able to finalize first, and where on the majority chain the victims will lose money faster than the attackers and so the attackers will be even stronger.
|
||||||
|
|
||||||
|
The asymmetry can be broken because users can manually implement a "user activated soft fork" where they refuse to accept the majority (attacking) chain, and so they can simply wait until the minority chain sheds deposits to the point where a checkpoint can be finalized by the non-colluding nodes. This coordination can be partially automated, as online nodes will be able to detect censorship, but it's impossible to make the automation perfect (as a perfect solution would violate impossibility results in distributed consensus); hence, a preferred solution is for nodes to give an alert if they believe the majority chain is attacking, and give the user an option of whether to continue with the majority chain or fork to the minority chain.
|
||||||
|
|
||||||
|
### Dealing with Failures in Proof of Work
|
||||||
|
|
||||||
|
In this kind of design, the underlying chain is still generated by proof of work. However, there is much less need to worry about 51% attacks on the proof of work for several reasons.
|
||||||
|
|
||||||
|
There are three kinds of 51% attacks in proof of work:
|
||||||
|
|
||||||
|
* **After the fact finality reversion** - make a chain longer than the existing main chain, reverting a large number of blocks at the end of the existing main chain that were thought to be finalized.
|
||||||
|
* **Equivocation** - create two "main chains" A and B that both appear long enough to be the main chain; convince one actor that A is finalized and another actor that B is finalized.
|
||||||
|
* **Censorship** - refuse to include blocks and transactions from other miners.
|
||||||
|
|
||||||
|
Finality reversion is impossible outright for miners to carry out, as finality is defined by the finality gadget and not proof of work; this immediately eliminates the worst kind of 51% attack. Equivocation can be used to prevent finality by repeatedly creating multiple chains with different checkpoints for each epoch, so that validators never manage to put two thirds of their prepares behind a single one. Censorship can be used to prevent validators from being rewarded, along with the first-order consenquences of making the chain unusable.
|
||||||
|
|
||||||
|
If worse comes to worst, equivocation can be dealt with manually by having validators come together over an out-of-band communication channel to coordinate on finalizing checkpoints until a hard fork to replace the proof of work can be conducted. However, there is also another more automatable approach: validators can start ignoring checkpoints unless their proof of work meets a higher difficulty threshold. Suppose that malicious miners have an n:1 advantage against honest miners, and malicious miners need to create c competing checkpoints to reliably prevent convergence (say, c = 3, as if c = 2 then one of the two may easily get two thirds prepares by random chance). This will eventually lead to the situation where the malicious miners will attempt to create c admissible checkpoints and publish them simultaneously, and ~1 - c/n of the time they will succeed, but the other c/n of the time an honest miner will create a single checkpoint first, and the consensus will move forward.
|
||||||
|
|
||||||
|
Censorship can be dealt with by having validators refuse to prepare checkpoints that do not include values that they believe should have been prepared.
|
||||||
|
|
||||||
|
### Discouragement Attacks
|
||||||
|
|
||||||
|
Perhaps the most difficult kind of attack to deal with in this algorithm is a "discouragement attack". This attack happens in two stages. First, an attacker engages in a medium-grade liveness degradation attack, with the main goal of reducing the rewards for honest validators to below zero, or at least to below their capital lockup costs. Then, the attacker engages in more serious attacks on liveness or safety against a much smaller pool of honest validators. A discouragement attack requires the attacker to have an amount of deposits equal to 1/3 of the original total deposit size, but allows them to trigger liveness and safety failures much more cheaply.
|
||||||
|
|
||||||
|
It is worth noting that proof of work is extremely vulnerable to discouragement attacks: assuming a competitive market where miners have low profits, a selfish mining attack can quickly force other miners offline, at which point the miner can engage in a 51% attack. Hence, even if our treatment of discouragement attacks is not fully satisfactory, it arguably still fares substantially better than other protocols.
|
||||||
|
|
||||||
|
Along with minimizing griefing factors, we can mitigate discouragement attacks using another strategy: those who are currently non-validators can coordinate on joining the validator set en masse, overwhelming the attacker to the point that their share of the total validator set is less than 1/3 and their griefing is no longer effective. We expect many to be willing to join altruistically, but we can also recycle a portion of penalties into future rewards, thereby temporarily increasing the incentive for new joiners.
|
||||||
|
|
@ -0,0 +1,68 @@
|
||||||
|
# Computes griefing factors of various parameter sets for Casper the
|
||||||
|
# Friendly Finality Gadget
|
||||||
|
|
||||||
|
# Case 1: <1/3 non-commit (optimal if epsilon participate)
|
||||||
|
def gf1(x1, x2, x3, x4, x5):
|
||||||
|
return x2 / x1
|
||||||
|
|
||||||
|
# Case 2: censor <1/3 committers (optimal if 1/3 get censored)
|
||||||
|
def gf2(x1, x2, x3, x4, x5):
|
||||||
|
return 1.5 * (x1 + x2 / 3) / x2
|
||||||
|
|
||||||
|
# Case 3: <1/3 non-prepare (optimal if epsilon participate)
|
||||||
|
def gf3(x1, x2, x3, x4, x5):
|
||||||
|
return x4 / x3
|
||||||
|
|
||||||
|
# Case 4: censor <1/3 preparers (optimal if 1/3 get censored)
|
||||||
|
def gf4(x1, x2, x3, x4, x5):
|
||||||
|
return 1.5 * (x3 + x4 / 3) / x4
|
||||||
|
|
||||||
|
# Case 5: finality preventing 1/3 non-commits
|
||||||
|
def gf5(x1, x2, x3, x4, x5):
|
||||||
|
return 2 * (x5 + x2 / 3) / (x5 + x1 + x2 / 3)
|
||||||
|
|
||||||
|
# Case 6: censor commits
|
||||||
|
def gf6(x1, x2, x3, x4, x5):
|
||||||
|
# Case 6a: 51% participate
|
||||||
|
return max(1 + x2 / (x5 + x1 + x2 / 2),
|
||||||
|
# Case 6b: 67% participate
|
||||||
|
(x5 + x1 + x2 / 3) / (x5 + x2 / 3) / 2)
|
||||||
|
|
||||||
|
# Case 7: finality and commit-preventing 1/3 non-prepares
|
||||||
|
def gf7(x1, x2, x3, x4, x5):
|
||||||
|
return 2 * (x5 + x4 / 3) / (x5 + x3 + x4 / 3)
|
||||||
|
|
||||||
|
gfs = (gf1, gf2, gf3, gf4, gf5, gf6, gf7)
|
||||||
|
|
||||||
|
# Get the maximum griefing factor of a set of parameters
|
||||||
|
def getmax(*args):
|
||||||
|
return max([f(*args) for f in gfs])
|
||||||
|
|
||||||
|
# Get the maximum <50% griefing factor, and enforce a bound
|
||||||
|
# of MAX_CENSOR_GF on the griefing factor of >50% coalitions
|
||||||
|
def getmax2(*args):
|
||||||
|
MAX_CENSOR_GF = 2
|
||||||
|
if gf2(*args) > MAX_CENSOR_GF or gf4(*args) > MAX_CENSOR_GF or \
|
||||||
|
gf6(*args) > MAX_CENSOR_GF:
|
||||||
|
return 999999999999999999
|
||||||
|
|
||||||
|
return max(gf1(*args), gf3(*args), gf5(*args), gf7(*args))
|
||||||
|
|
||||||
|
# Range to test for each parameter
|
||||||
|
my_range = [i/12. for i in range(1, 61)]
|
||||||
|
|
||||||
|
best_vals = (1, 0, 0, 0, 0)
|
||||||
|
best_score = 999999999999999999
|
||||||
|
|
||||||
|
for x1 in my_range:
|
||||||
|
for x2 in my_range:
|
||||||
|
for x3 in my_range:
|
||||||
|
for x4 in my_range:
|
||||||
|
o = getmax2(x1, x2, x3, x4, 1)
|
||||||
|
if o < best_score:
|
||||||
|
best_score = o
|
||||||
|
best_vals = (x1, x2, x3, x4, 1)
|
||||||
|
if o <= 1:
|
||||||
|
print((x1, x2, x3, x4, 1), [f(x1, x2, x3, x4, 1) for f in gfs])
|
||||||
|
print('result', best_vals, best_score)
|
||||||
|
print([f(*best_vals) for f in gfs])
|
||||||
|
|
@ -0,0 +1,31 @@
|
||||||
|
import math
|
||||||
|
|
||||||
|
# Length of an epoch in seconds
|
||||||
|
epoch_len = 1400
|
||||||
|
# In-protocol penalization parameter
|
||||||
|
increment = 0.00002
|
||||||
|
|
||||||
|
# Parameters
|
||||||
|
NFP = 0
|
||||||
|
NCP = 3
|
||||||
|
NCCP = 3
|
||||||
|
NPP = 3
|
||||||
|
NPCP = 3
|
||||||
|
|
||||||
|
def sim_offline(p):
|
||||||
|
online, offline = 1-p, p
|
||||||
|
for i in range(1, 999999):
|
||||||
|
# Lost by offline validators
|
||||||
|
offline_loss = NFP + NPP + NPCP * offline
|
||||||
|
# Lost by online validators
|
||||||
|
online_loss = NFP + NPCP * offline
|
||||||
|
online *= 1 - increment * math.log(i) * online_loss
|
||||||
|
offline *= 1 - increment * math.log(i) * offline_loss
|
||||||
|
if i % 100 == 0 or online >= 2 * offline:
|
||||||
|
print("%d epochs (%.2f days): online %.3f offline %.3f" %
|
||||||
|
(i, epoch_len * i / 86400, online, offline))
|
||||||
|
# If the remaining validators can commit, break
|
||||||
|
if online >= 2 * offline:
|
||||||
|
break
|
||||||
|
|
||||||
|
sim_offline(0.4)
|
||||||
Loading…
Reference in New Issue