* Harden handling of unviable forks In our current handling of unviable forks, we allow peers to send us blocks that come from a different fork - this is not necessarily an error as it can happen naturally, but it does open up the client to a case where the same unviable fork keeps getting requested - rather than allowing this to happen, we'll now give these peers a small negative score - if it keeps happening, we'll disconnect them. * keep track of unviable forks in quarantine, to avoid filling it with known junk * collect peer scores in single module * descore peers when they send unviable blocks during sync * don't give score for duplicate blocks * increase quarantine size to a level that allows finality to happen under optimal conditions - this helps avoid downloading the same blocks over and over in case of an unviable fork * increase initial score for new peers to make room for one more failure before disconnection * log and score invalid/unviable blocks in requestmanager too * avoid ChainDAG dependency in quarantine * reject gossip blocks with unviable parent * continue processing unviable sync blocks in order to build unviable dag * docs * Update beacon_chain/consensus_object_pools/block_pools_types.nim * add unviable queue test |
||
|---|---|---|
| .. | ||
| README.md | ||
| request_manager.nim | ||
| sync_manager.nim | ||
| sync_protocol.nim | ||
| sync_queue.nim | ||
README.md
Block syncing
This folder holds all modules related to block syncing
Block syncing uses ETH2 RPC protocol.
Reference diagram
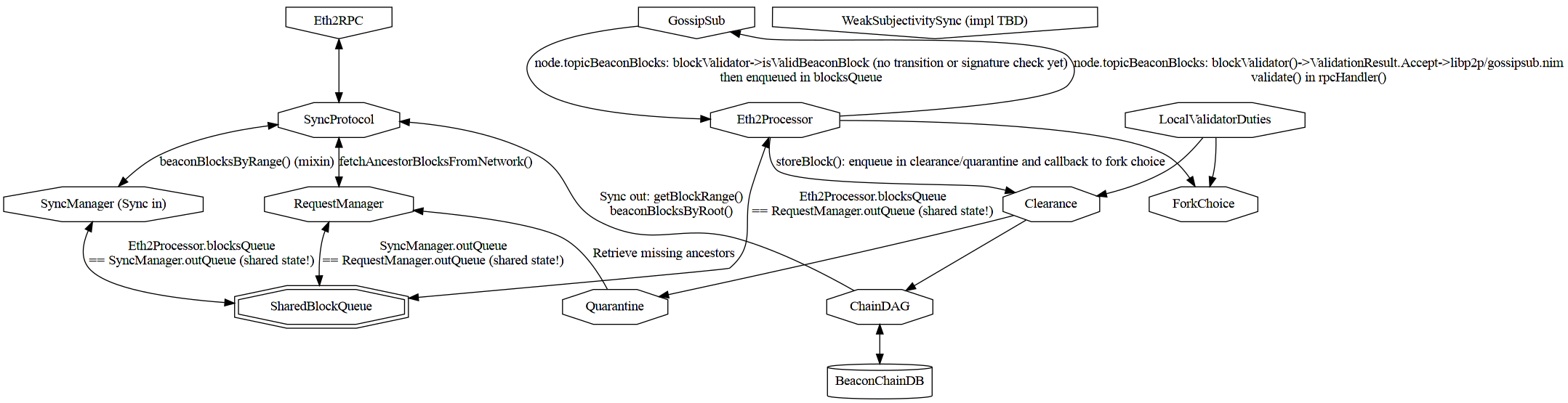
Eth2 RPC in
Blocks are requested during sync by the SyncManager.
Blocks are received by batch:
syncStep(SyncManager, index, peer)- in case of success:
push(SyncQueue, SyncRequest, seq[SignedBeaconBlock]) is called to handle a successful sync step. It callsvalidate(SyncQueue, SignedBeaconBlock)` on each block retrieved one-by-onevalidateonly enqueues the block in the SharedBlockQueueAsyncQueue[BlockEntry]but does no extra validation only the GossipSub case
- in case of failure:
push(SyncQueue, SyncRequest)is called to reschedule the sync request.
Every second when sync is not in progress, the beacon node will ask the RequestManager to download all missing blocks currently in quarantaine.
- via
handleMissingBlocks - which calls
fetchAncestorBlocks - which asynchronously enqueue the request in the SharedBlockQueue
AsyncQueue[BlockEntry].
The RequestManager runs an event loop:
- that calls
fetchAncestorBlocksFromNetwork - which RPC calls peers with
beaconBlocksByRoot - and calls
validate(RequestManager, SignedBeaconBlock)on each block retrieved one-by-one validateonly enqueues the block in theAsyncQueue[BlockEntry]but does no extra validation only the GossipSub case
Weak subjectivity sync
Not implemented!
Comments
The validate procedure name for SyncManager and RequestManager
as no P2P validation actually occurs.
Sync vs Steady State
During sync:
- The RequestManager is deactivated
- The syncManager is working full speed ahead
- Gossip is deactivated
Bottlenecks during sync
During sync:
- The bottleneck is clearing the SharedBlockQueue
AsyncQueue[BlockEntry]viastoreBlockwhich requires full verification (state transition + cryptography)
Backpressure
The SyncManager handles backpressure by ensuring that
current_queue_slot <= request.slot <= current_queue_slot + sq.queueSize * sq.chunkSize.
- queueSize is -1, unbounded, by default according to comment but all init paths uses 1 (?)
- chunkSize is SLOTS_PER_EPOCH = 32
However the shared AsyncQueue[BlockEntry] itself is unbounded.
Concretely:
- The shared
AsyncQueue[BlockEntry]is bounded for sync - The shared
AsyncQueue[BlockEntry]is unbounded for validated gossip blocks
RequestManager and Gossip are deactivated during sync and so do not contribute to pressure.